
Next.js 블로그 검색엔진 최적화(SEO) 도입기
FE 개발자 관점에서 Next.js 환경 블로그에 도입한 SEO 전략
- 직접 개발 블로그를 만들면 많은 자유를 얻을 수 있다.
- 하지만 마냥 좋은 것은 아니다. 그만큼 신경써야 할 요소도 많아지기 때문이다.
- 그중에서도 특히 중요하게 고려해야 할 요소는 단연 검색엔진 최적화 (SEO)라고 생각한다.
- 공들여 만든 포스팅이 아무런 관심도 받지 못한 채 웹 속에 파묻혀있다면 얼마나 속상할까?
- 이 글에서는 NextJS로 직접 개발한 블로그에 SEO를 어떻게 도입했는지에 대해 정리했다.
포스팅 페이지 렌더링 전략
- 포스트 페이지는 블로그 검색 노출에 있어 가장 핵심적인 영역이다.
- 그렇기에 렌더링 설계 역시 중요하게 고려했으며, 포스트 데이터를 어떤 방식으로 관리하느냐를 기준으로 구분했다.
- 우선, CSR 방식과 SSR 방식은 제외했다.
- CSR은 초기 렌더 시점에 HTML 콘텐츠가 비어 있어 검색엔진 친화적이지 않았고, SSR은 포스트 특성상 매 요청마다 서버에서 새로 렌더링할 필요성이 크지 않다고 판단했다.
- 결과적으로 SSG와 ISR 사이에서 고민했으며 다음과 같은 차이가 있었다.
SSG (Static Site Generation)
- SSG 는 빌드 시점에 모든 HTML을 미리 생성하는 방식이다.
- 생성된 페이지는 정적 파일로 CDN을 통해 즉시 제공되기 때문에 응답 속도와 SEO 측면에서 매우 유리하다.
- 다만, 포스트를 수정하거나 추가할 경우 전체 빌드 및 배포 과정이 필요하다는 단점이 있다.
ISR (Incremental Static Regeneration)
- ISR은 SSG의 정적 페이지 제공 방식을 유지하면서 특정 조건에서 해당 페이지를 다시 생성할 수 있도록 확장한 렌더링 전략이다.
- CMS(Content Management System)와 같은 외부 데이터 저장소를 통해 포스팅을 관리하는 경우, 전체 빌드를 다시 수행하지 않고 변경 페이지를 갱신할 수 있다는 장점이 있다.
- 반면, On-Demand Revalidation API, WebHook등 운영측에서 고려해야할 요소 역시 많아진다.
나는 SSG + MD 방식의 관리를 선택했다
당장 ISR 방식의 이점이 필요가 없었기 때문이다.
포스팅의 수정 빈도가 높지 않을것을 예상했고, 배포 역시 Vercel 연동으로 자동화 되어있었다.
또한 포스팅의 양이 많지 않아 레포지토리에서 코드와 함께 리소스를 관리하더라도 부담이 크지 않았다.
그렇기에 ISR을 통해 재검증 트리거를 설계하는것은 현시점에서 오버엔지니어링이라고 판단했다.
무엇보다도, 추후 포스팅 수가 늘어나거나 CMS 도입이 필요하다면 그 시점에 전환해도 충분히 대응 가능할 것 같았다.
메타 태그 관리
- 메타 태그는 페이지의 핵심 정보(=메타 데이터)를 담고 있으며, 검색엔진이나 크롤러가 페이지를 이해하는 데 사용하는 가장 기초적인 단서이다.
- 템플릿이 되는 공통 메타데이터와 페이지별 세부 메타데이터를 분리하여 관리하였다.
// app/layout.tsx
export const metadata: Metadata = {
metadataBase: new URL("https://www.changchangwoo.com"),
title: {
default: "Changchangwoo's blog",
template: "%s | Changchangwoo 블로그",
},
description: "프론트엔드 개발자 이창우의 블로그입니다.",
openGraph: {
type: "website",
locale: "ko_KR",
siteName: "Changchangwoo 블로그",
title: "Changchangwoo's blog",
description: "프론트엔드 개발자 이창우의 블로그입니다.",
images: [
{
url: "/images/common/og_img.png",
width: 1200,
height: 630,
alt: "Changchangwoo's blog",
},
],
},
};
// app/post/[...slug]/page.tsx
export async function generateMetadata({ params }: PostPageProps) {
const post = getPostBySlug(params.slug.join("/"));
if (!post) {
return { title: "Post Not Found", robots: { index: false } };
}
return {
title: post.title,
description: post.description,
openGraph: {
title: post.title,
description: post.description,
type: "article",
publishedTime: post.date,
tags: post.tag,
images: post.coverImage
? [
{
url: post.coverImage,
width: 1200,
height: 630,
alt: post.title,
},
]
: [],
},
};
}
- Next의
App Router메타데이터는 계층적 모델이기에 상속과 병합 구조를 제공한다. - 최상위 layout에서 사이트 전반에 적용되는 메타 데이터 템플릿을 정의하였다.
- 각 세부페이지에서는 Next에서 빌트인 동적 메타 데이터 생성 함수
generateMetaData를 통해 필요한 값만 오버라이드 하도록 구성했다. - 이를 통해서 일관적인 메타태그 구조를 가져갈 수 있었다.
- 또, 각 페이지마다 canonical 태그를 오버라이드 하도록해 페이지별 대표 URL을 명시했다.
export const metadata = {
alternates: {
canonical: "https://www.changchangwoo.com/",
},
};
- 핵심 메타 데이터는 다음과 같다.
title: 브라우저 탭 제목이며, 검색 결과에 노출되는 아주 중요한 텍스트이다.description: 검색결과에 표시될 웹 페이지의 간략한 요약문을 제공한다.metadataBase: 상대 경로로 작성한 메타 정보를 절대 경로로 변환한다.canonical: 유사한 컨텐츠가 여러 URL로 접근 가능한 경우, 대표 URL을 명확히 인식하도록 도와 중복 URL을 방지할 수 있도록 도와준다.openGraph: SNS 공유시 출력되는 미리보기 내용이다.
| open_graph1 | open_graph2 |
|---|---|
 |
 |
시맨틱 태그
- 시맨틱 태그는 단순히 마크업을 위한 요소가 아니라, 검색 엔진이 페이지의 구조와 역할을 이해하도록 돕는 장치다.
- 따라서 레이아웃을 설계 할 때 최대한 의미와 역할을 기준으로 구성할 수 있도록 태그를 선택했다.
- 또한 구조를 직관적으로 나누기에 SEO뿐만 아니라 코드 가독성도 향상 시킨다.
- 특히, Heading 제목 계층이 순차적으로 구분되어지지 않는 경우가 많았다.
- 페이지 내 h1은 단하나만 존재해야하며, h2, h3는 순서 계층을 유지해야한다.
Robots.txt, Sitemap.xml
- 검색 엔진 크롤러가 사이트를 효율적으로 탐색할 수 있도록
robots.txt와sitemap.xml을 함께 구성하였다. robots.txt는 크롤러의 접근 범위를 제어하고,sitemap.xml은 사이트의 구조와 주요 페이지 정보를 명시적으로 제공한다.
// app/sitemap.ts
export default function sitemap(): MetadataRoute.Sitemap {
const baseUrl = "https://www.changchangwoo.com";
return [
{
url: baseUrl,
lastModified: new Date(),
priority: 1.0,
},
...getAllPosts().map((post) => ({
url: `${baseUrl}/post/${post.slug}`,
lastModified: new Date(post.date),
priority: 0.9,
})),
];
}
- 사이트맵은 정적 페이지 뿐 아니라, 동적 라우트로 생성되는 페이지까지 포함하는 것이 중요하다.
- Next.js에서 제공하는
MetadataRoute.Sitemap을 활용해 빌드 시점에 이를 고려한sitemap.xml을 자동을 생성하도록 구현하였다.
페이지 성능 분석
- 검색엔진은 콘텐츠와 구조뿐만 아니라 페이지 성능 또한 주요 평가 요소로 고려한다.
- 그렇기에 건강한 Core web Vitals(LCP, CLS, FID) 지표가 매우 중요하다.
| 데스크탑 | 모바일 |
|---|---|
 |
 |
-
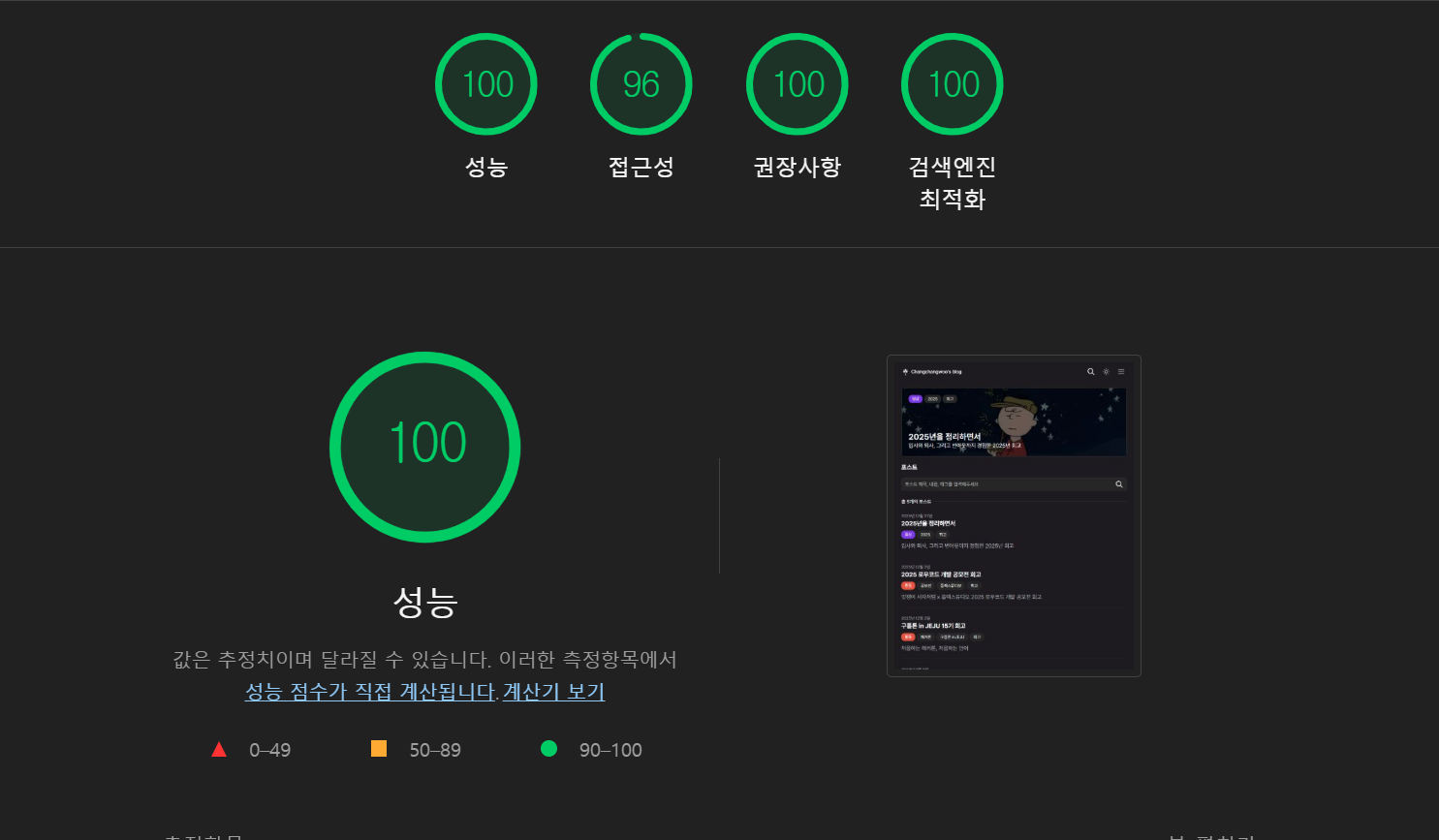
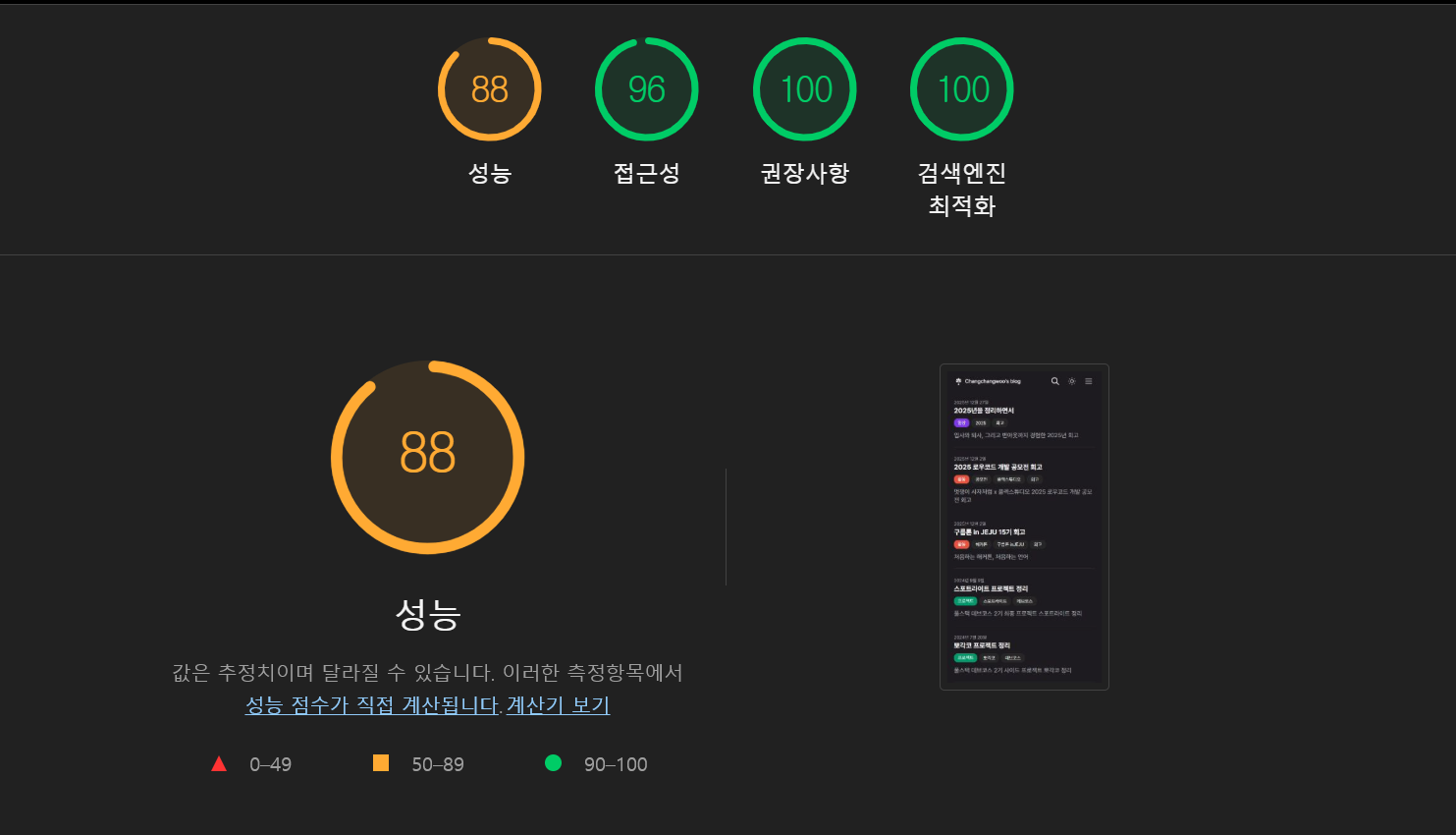
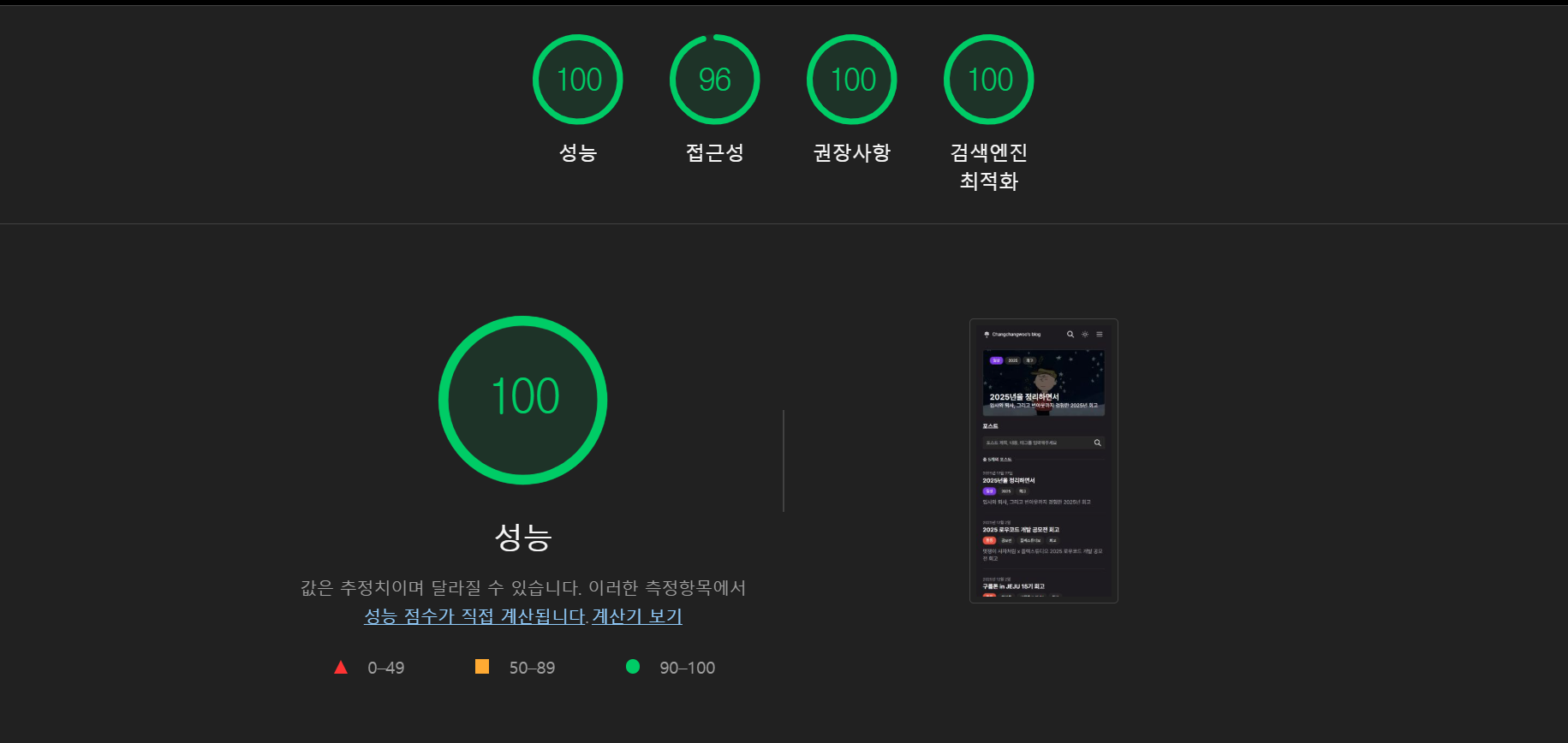
우선적으로 LIGHT HOUSE를 통해 데스크톱과 모바일 환경의 페이지 성능을 분석했다.
-
분석 결과 데스크탑에서는 충분히 최적화가 되었지만, 모바일에서는 여러 개선점을 발견할 수 있었다.
-
모바일 환경에서의 최적화가 특히 중요한데, Google을 비롯한 여러 검색엔진들은 Mobile-First Indexing정책을 적용하고 있어, 모바일 성능이 SEO에 직접적인 영향을 미치기 때문이다.
-
개선 사항은 다음과 같다
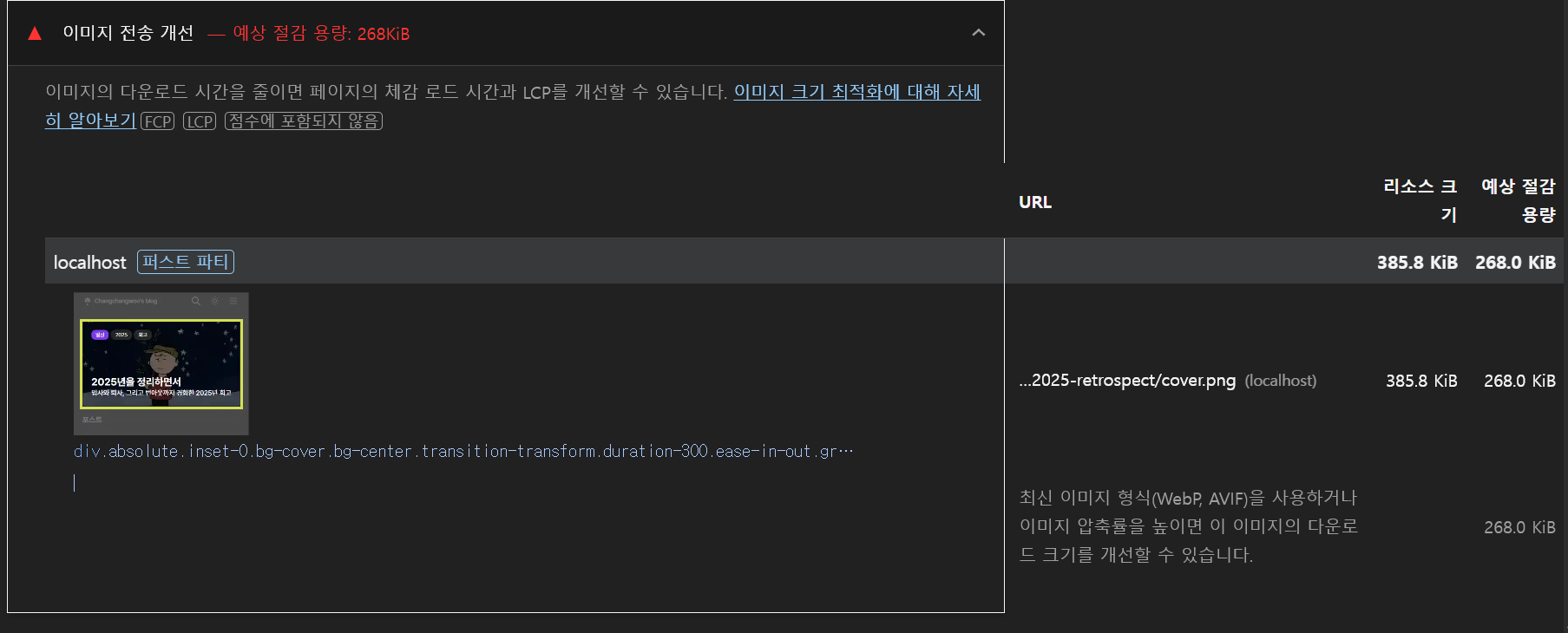
- 메인 영역에 노출되는 PinnedPost가
next/image를 사용하지 않아 이미지 최적화가 적용되어지지 않고 있었다. 이를 교체했다. - 블로그 검색에 대한 기능을 QueryString 기반으로 구현했으나, 디바운싱 처리가 누락되어 타이핑 마다 요청이 발생하고 있었다. 200ms 디바운싱을 적용해 요청 수를 줄였다.
- 메인 영역에 노출되는 PinnedPost가
non-www, wwwURL 분리
- 동일한 사이트가 www와 non-www 두 도메인으로 접근이 가능한 경우, 검색엔진은 이를 중복 콘텐츠로 인식할 수 있다.
- 중복 콘텐츠는 색인 분산, SEO 평가 저하로 이어질 수 있기에 하나의 정규 도메인으로 통일하는 것이 중요하다.
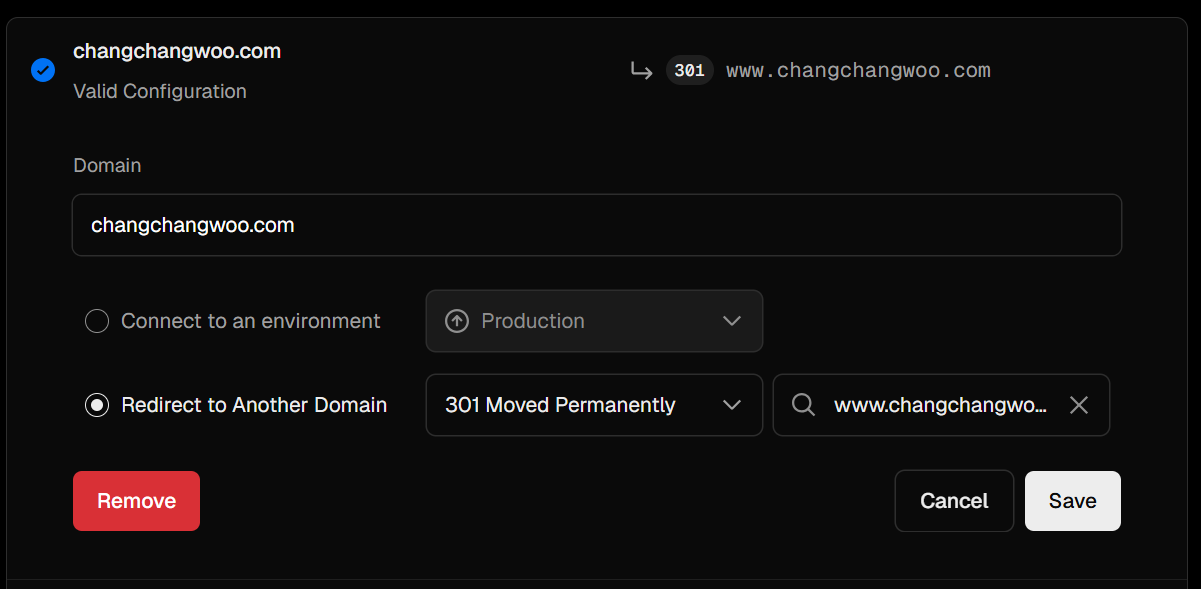
- 그렇기 때문에, non-www로 접근했을 때 www로 도메인으로 리디렉션 설정을 해주었다.
- Vercel의 도메인 관리 기능을 활용해 별도의 설정 없이 간단하게 적용할 수 있었다.
구글 서치 콘솔을 통한 색인 관리
- SEO를 적용한 사이트 배포 이후, Google Search Console에 도메인 속성으로 사이트를 등록하고
sitemap.xml을 제출하여 크롤링 및 색인을 유도했다.
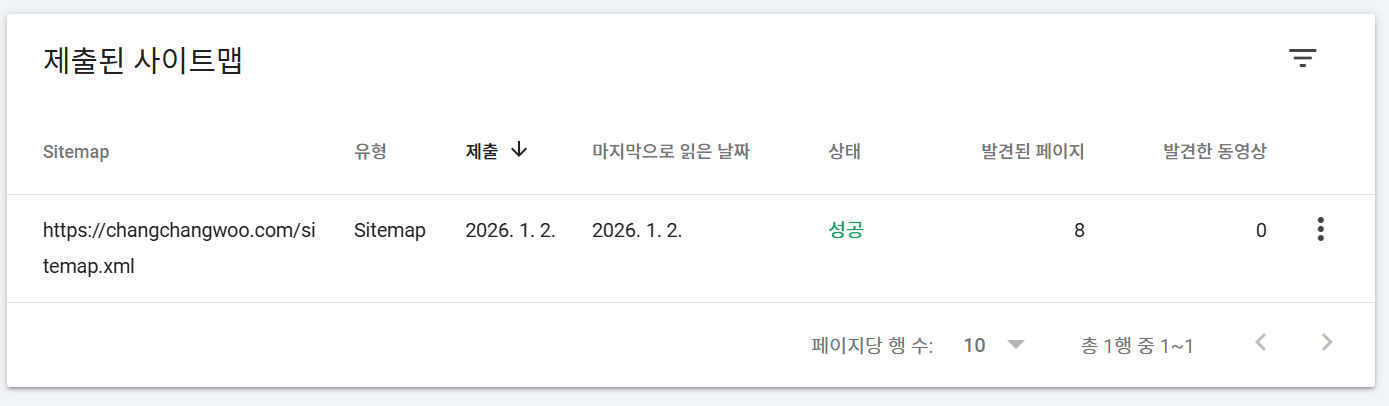
- 구글 서치 콘솔을 통해서 페이지가 정상적으로 색인되고 있는지, 검색 결과에 노출되고 있는지 주요 지표(노출수, 클릭 수, CTR, 평균 게재순위)를 대시보드 형태로 지속적으로 관찰할 수 있다.
- 현재는 사이트 배포 초기 단계로, 아직 유의미한 색인 데이터는 쌓이지 않았지만 향후 다음과 같은 기준으로 서치 콘솔을 운영할 계획이다.
- 검색어 기준으로 의도한 키워드가 노출이 되어 있는지 확인
- 노출 대비 CTR이 낮은 페이지에 대한 메타데이터 개선
- 노출이 자주 발생하는 페이지를 기준으로 콘텐츠 확장
마치며
- 프로젝트를 진행할 수록, 사용자 확보에 대한 욕심과 SEO에 대한 중요성을 크게 체감하고 있다.
- 이번에 블로그를 개발하며, 어렴풋이 적용했던 SEO 내용들의 개념을 확실히 잡고 갈 수 있었다.
- 블로그 초기 설정 단계에서 최적화 구조를 잡아두었으니 지속적으로 색인을 확인하며 개선해나갈 예정이다.
- 추후에 유의미한 지표를 바탕으로 회고를 작성할 수 있었으면 좋겠다.
- 물론 SEO는 시작일 뿐이고 양질의 컨텐츠를 만드는건 또 다른 영역이지만, 모두 충족하는 블로그를 만들어가는 과정이 앞으로의 과제라고 생각한다.